InnoDB为啥用B+树做索引结构
- Hash索引
Hash只能做精确的等值查询,不能做部分匹配,不能做范围查询,不能排序 - 有序数组
数组对于增删操作需要移动后面的数据 - 平衡二叉查找树
数据量大时,树的高度相对会大,中序遍历可以得到一个有序序列,但是不足以按照区间快速查找数据 - B树
不能支持范围查询,排序 - B+树
叶子节点是一个有序链表 - 跳跃表
类似与B+树,也是可以的
InnoDB数据存储方式
MySQL的数据是存储在聚簇索引上的,MySQL的每个表会按照主键建立一个聚簇索引,每行数据挂在B+树的叶子节点上,非聚簇索引的叶子节点除了索引字段的值,还会存储主键的值。如果使用了非聚簇索引,而且还需要查找索引字段之外的字段值,这时候就需要使用主键进行回表操作。
聚簇索引
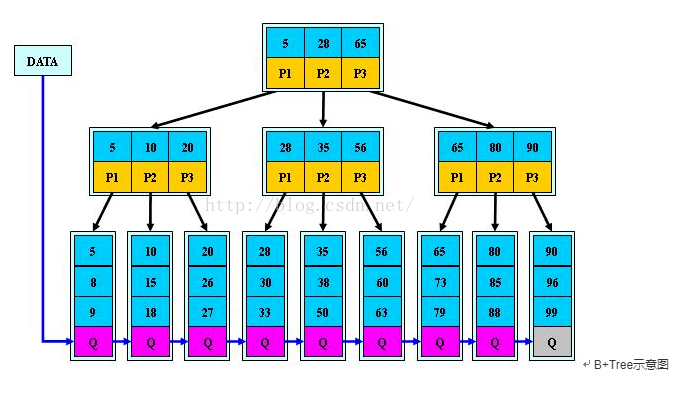
- InnoDB基于主键建立聚簇索引
- 没有主键,会用唯一索引建立
- 没有唯一索引,InnoDB会定义一个隐藏的主键,然后对其建立聚簇索引
InnoDB默认使用聚簇索引来组织数据,如果你用InnoDB,而且不需要特殊的聚簇索引,一个好的做法就是使用代理主键(surrogate key)——独立于你的应用中的数据。最简单的做法就是使用一个AUTO_INCREMENT的列,这会保证记录按照顺序插入,而且能提高使用primary key进行连接的查询的性能。应该尽量避免随机的聚簇主键,例如字符串主键就是一个不好的选择,它使得插入操作变得随机,不是按顺序插入,会产生页分裂、页合并等操作。
非聚簇索引(二级索引)
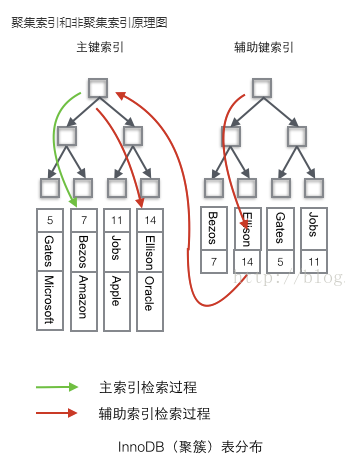
InnoDB索引
聚簇索引
二级索引
组合索引
在多个列上建立的联合索引,对比单字段索引
覆盖索引
select筛选的字段都在索引包含的字段中,不需要进行回表操作
最左前缀
组合索引是按照字段从左到右排序来组织索引的,从中间字段开始比较不是按序的,无法使用到索引,必须第一字段开始,不能跳过中间字段使用后面的字段。如12345组合索引(a, b, c)可以用到的索引aa, ba, b, c
前缀索引
可以在字符串字段上基于字符串前多少个字符建立前缀索引,这种索引的优势是减少索引空间
索引下推
|
|
唯一索引
普通索引允许被索引的数据列包含重复的值。而唯一索引列的值必须唯一,但允许有空值。如果是组合索引,则列值的组合必须唯一
- 唯一索引在查询的时候可以唯一确定一行,所以查到记录就会停止查询,而普通索引还有继续向后遍历到第一个不满足的条件为止
索引设计
- 尽量选择区分度高的列作为索引
区分度的公式是 COUNT(DISTINCT col) / COUNT(*) - NULL也是可以走索引的
- 使用组合索引代替多个列索引
- 注意重复/冗余的索引、不使用的索引
- 唯一索引
业务无法保证数据的唯一的时候,可以使用唯一索引通过数据库保证数据的唯一
索引选择
优化器基于代价进行索引选择,扫描行数(基于统计的)、是否使用临时表、是否排序等
索引选择异常处理
- force index (hard code)
- 修改sql引导mysql选择正确的索引
- 删掉误导的索引,新建合适的索引
索引使用
- like语句不要以通配符开头
在以通配符%和_开头作查询时,MySQL不会使用索引 - 不要在列上进行运算
表达式、函数 - 隐式类型转换、隐式字符编码转换、排序规则不一样 都不走索引
- 尽量不要使用NOT IN、<>、!= 操作
引擎放弃使用索引而进行全表扫描,使用>或<会比较高效 - in值太多时也是不走索引的,数据库有配置
- or条件
在or条件的每个字段上单独建立索引,也是可以走索引的,会走union合并 - 组合索引的使用要遵守“最左前缀”原则